www.youtube.com/watch?v=bNb2fEVKeEo&list=PL3FW7Lu3i5JvHM8ljYj-zLfQRF3EO8sYv&index=5
Stanford University에서 2017년도에 강의한 CS231n를 들으며 정리, 요약했다.
4강 Convolutional Neural Networks for Visual Recognition 강의 요약 시작!

intermediate feature 을 얻을 수 있다.
간략한 역사
1957 : 퍼셉트론
2012 : Alexnet
Convnet은 빠르게 발전하여 classification, detection, segmentation, image captioning 등에 이용된다
Fully Connected Layer

input을 쭉 펴서 행렬곱함
Convolution Layer

filters는 항상 input의 depth와 같은 depth를 가짐 (3)
5*5*3의 chunk가 하나의 값을 만듬
이렇게 모인 값들이 activation maps를 만듬
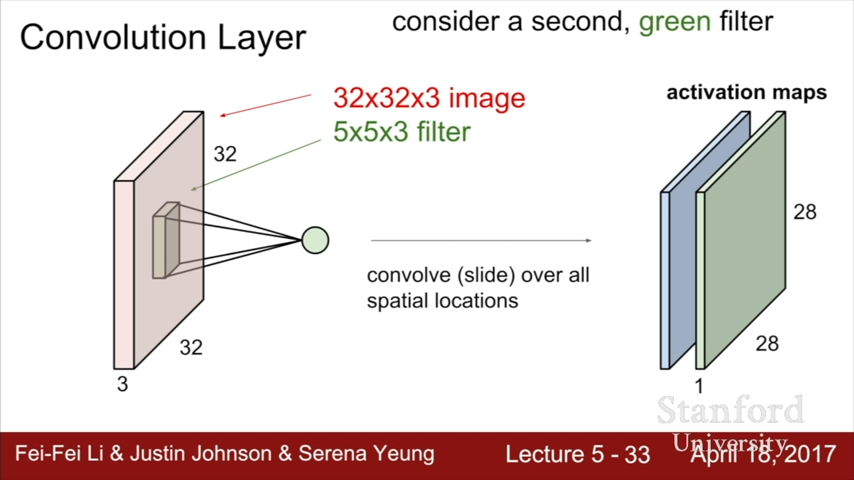


2번째 green filter가 이 과정을 반복해서 두번째 activation maps를 만들고, 이 과정이 반복됨
conv와 conv 사이에는 activation function이 들어감

low~high level features들
maximize neuron 하는 쪽으로 filter만들어짐

첫번째 filter는 (작은 네모) edge와 같은 activation function을 만들었다

conv와 relu를 거치면서 나오는 activation map


다시 여기로 돌아가서
filter가 slide하면서 output을 만듬
slide하는 간격을 stride라고 함


stride가 3이면 간격이 안맞다
공식화 시키면 저렇게 된다
실제로는 padding이라는 기법도 사용됨

(7+2 - 3) / 1 +1 = 6+1 = 7
이기에 7*7 output이 나온다
Zero padding을 하는 이유?
input size인 7*7을 maintain시켜주는 역할을 할 수 있기 때문

(F-1)/2 하면 원래 size유지 가능
padding안하면 deep network에서 점점 작아져서 사라질 것임
그러고 edge나 coner정보를 잃을 수도 있다.
Example

32*32*3
10 개의 5*5
그럼 (32+2*2-5)/1+1 = 32 size의 10 channel이 될 것이다
이 때, parameter의 수는?

(3*5*5+1)*10
input channel 수 * filter크기 =>하나의 filter의 parameter 수 이고
하나의 filter에 하나의 bias가 추가
Summary

1*1 convolution도 존재

Example : Torch and caffe


Conv와 Fully Connected Layer 비교


FC는 output 한점에 모든 input이 대응됨
conv는 5*5*3이 한 동그라미에 대응됨
Pooling Layer

Max Pooling

stride 2 pooling이다
최댓값만을 택함
왜 avg보다 max를 사용하나?
얼마나 neuron(filter)이 fire했나를 보여주는 지표이니 중요한 정보라고 볼 수 있어서
Stride vs Pooling
다운샘플링 시 요새는 stride를 더 많이 사용함, 선택사항이긴함
Summary

pooling에는 주로 padding을 사용하지 않음
ConvNetJS demo

Summary

'KAIST MASTER📚 > CS231n' 카테고리의 다른 글
| [CS231n] Lecture 4 - Introduction to Neural Networks (0) | 2021.02.01 |
|---|---|
| [CS231n] Lecture 3 - Loss Functions and Optimization (0) | 2021.01.31 |
| [CS231n] Lecture 2 - Image Classification (0) | 2021.01.30 |



댓글